Last updated: May 20, 2026
There are two ways to ask an AI platform a question and record what it says. You can call the platform's API and parse the JSON it returns. Or you can open a browser, type the question in the same box a customer would use, and read whatever shows up on the page.
Most AI visibility tools take the first path. We took the second. This page explains why, and what we accept in exchange.
Two surfaces, one platform
Every major AI provider runs two distinct surfaces against the outside world. One is the developer endpoint, built for engineers wiring the model into their own software. The other is the chat product, built for everyone else.
These look like the same thing. They aren't. The chat product sits on top of the model and adds layers the developer endpoint doesn't run by default: search retrieval, result ranking, citation rendering, inline product cards, source panels, follow-up suggestions, comparison tables generated on the fly. Each of those layers is a place where a brand can be cited, mentioned, or ignored. Almost none of them exist on the developer endpoint in usable form.
So the choice between API and browser isn't really technical. It's a choice about which surface you think matters.
Three places where the two surfaces diverge
The recommendations themselves can be different. Send the same question to both and you can get different brand mentions, different ordering, different citations. The chat product runs additional retrieval and ranking; the developer endpoint runs closer to the raw model. If you measure one and report on the other, the number you publish doesn't correspond to what anyone actually sees.
Whole features only exist in the chat product. Citation panels with clickable sources, follow-up suggestions, embedded product previews, comparison tables. These are product features, not model features. They're often where the most interesting brand visibility lives, and the developer endpoint either doesn't expose them or strips out the structure that makes them useful.
Backend contracts shift more than user interfaces. Developer endpoints get versioned, deprecated, throttled, and silently retuned. A measurement system anchored to those contracts inherits their instability. The chat product evolves too, but it's the surface providers commit to maintaining for their paying users, which makes it the slower-moving target.
What a "browser session" actually means in our system
UI scraping carries baggage. In many contexts it means brittle screen readers that pull text from fixed coordinates and break on every layout change. That isn't what we run.
We operate full browser sessions against each platform, on a regular schedule, against the same product surface customers use. Each session behaves like a person at their computer asking a question.
Four operational details matter:
- Sessions are logged-out. No account, no history. Logged-in answers are personalized to the individual user, which makes them impossible to aggregate cleanly. Logged-out is the common denominator across users who haven't customized anything.
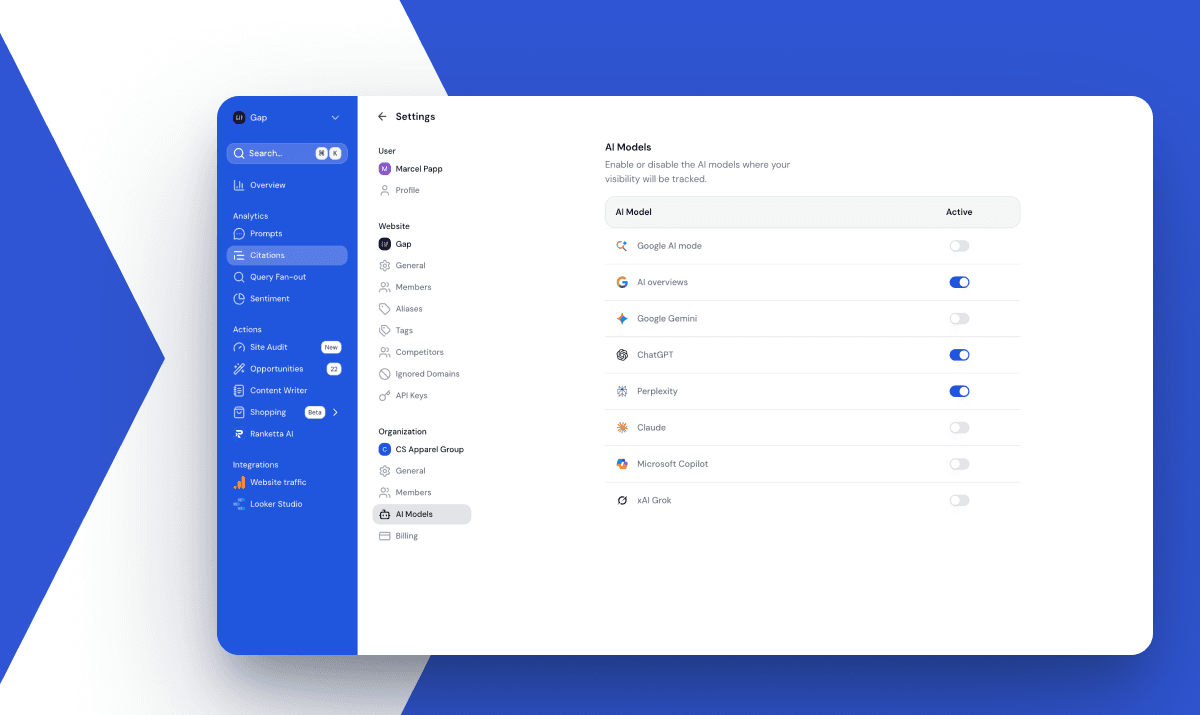
- Model selection stays on default. Whichever model a new visitor lands on is the one we use. Switching to a smarter paid model would inflate the numbers, but they wouldn't reflect what most users actually see.
- Web search behavior stays on default. When a platform decides on its own whether to run a live search or answer from training data, we don't override it. The platform's own decision is part of the product.
- Parsing happens against rendered output. We read responses from what the page displays, not from intermediate network calls. The rendered output is the contract between the platform and the user, and it's the contract between the platform and us.
What this approach unlocks
Going through the browser isn't only about avoiding sanitized data. It opens up signal that isn't reachable through the developer endpoint at all.
Surfaces with no developer endpoint. Google AI Overviews and Google AI Mode are the clearest examples. Neither has a public endpoint suited to visibility tracking. The browser is the only direct route.
Product-layer features. Citations, source panels, follow-up suggestions, embedded comparison cards. These carry real visibility weight, and they live in the product layer. Reading them from anywhere else means losing them.
The platform's own defaults. Which model gets invoked, whether to search the web, which sources to surface. API callers have to set all of this explicitly, which means they're choosing a configuration rather than observing one.
Geographic localization. Every prompt runs as a session located in a specific country. Which sources the platform prefers in that market, which language it defaults to, which regional businesses it surfaces, all of that is product behavior. Measuring it requires being inside that surface.
What we give up to do this
Browser-based measurement isn't a strict upgrade. Three costs are worth naming.
Operations are heavier. A developer endpoint call returns JSON in a second or two. A full browser session takes longer, costs more compute, and needs orchestration for login walls, rate limits, anti-bot defenses, and the steady drift of how each platform renders responses. The reason most competitors skip this isn't that they don't see the value. It's that the value comes with a bill they don't want to pay.
Sampling is slower per unit. Because each session costs more, we run on a weekly cadence rather than continuously. The trade-off is fine for visibility tracking, which is a trend phenomenon, not a real-time one.
Maintenance is continuous. Every platform changes its product surface regularly, and our scraping logic has to keep up. We treat that as a permanent line item. The honest comparison is that API-based measurement has the same maintenance load, just routed through endpoint deprecation instead of layout changes.
The bottom line
API access is easier. It scales cheaply, returns fast, produces clean structured data. It's also a different surface than the one your customers use, which means the visibility numbers it produces describe a different reality than the one your customers experience.
We built Ranketta around browser sessions because the question we exist to answer is "what do AI tools actually show people about your brand". The only way to answer that without losing information is to look at what AI tools actually show people. Same interface, same defaults, same point in the journey.
For the full measurement framework behind these numbers, see How Ranketta Measures AI Visibility. Questions or pushback on this approach? Write to us.