AI shopping assistants recommend products by retrieving structured data and reasoning over it, not by reading your marketing copy.
That one fact reshapes what "good product data" means. It has to be complete, identifiable, and written in the language people actually use when they ask. None of that happens by default. Shopping-related use of generative AI grew 35% between February and November 2025 (BCG, 2026), so the products that are easy for AI to parse are quietly gaining ground right now.
This is less a content problem than a data problem, and most teams are still treating it as the first.
Here are three fixes to your product data, plus one supporting layer, that work whether you sell 10 products or 10,000.
How an AI actually picks a product
When an AI recommends a product, it isn't reading the description on your page.
Your product data isn't the paragraph under the photo. It's a feed, a set of identifiers, and a trail of signals scattered across the web. The model pulls from those wherever it can find them, and they travel two main routes.
The first route is structured feeds. In Google's case that means Google Merchant Center, which syncs your catalog into the Shopping Graph, the product database behind Search, Gemini, AI Mode and AI Overviews. The same feed that powers your Shopping ads is what populates those AI recommendations, and it holds tens of billions of listings refreshed constantly. One feed, many surfaces.
The second route is open retrieval. Tools like ChatGPT and Perplexity build answers by pulling from your product pages, comparison sites, marketplaces and reviews, then reasoning over what they find.
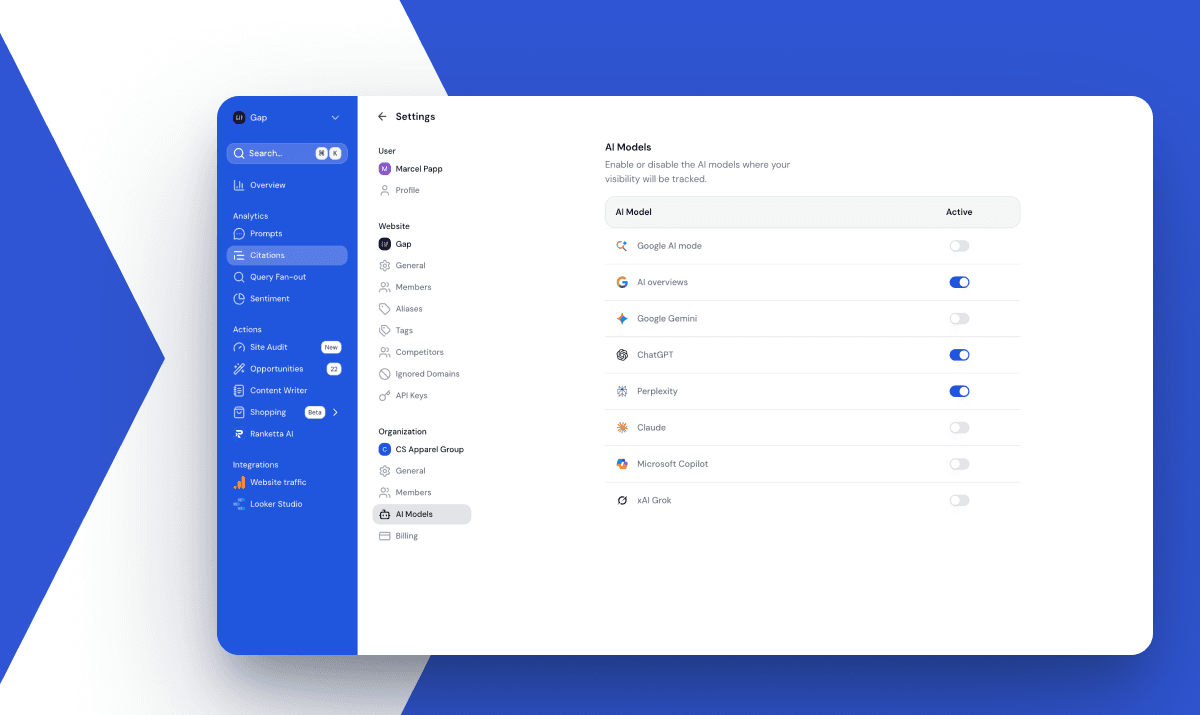
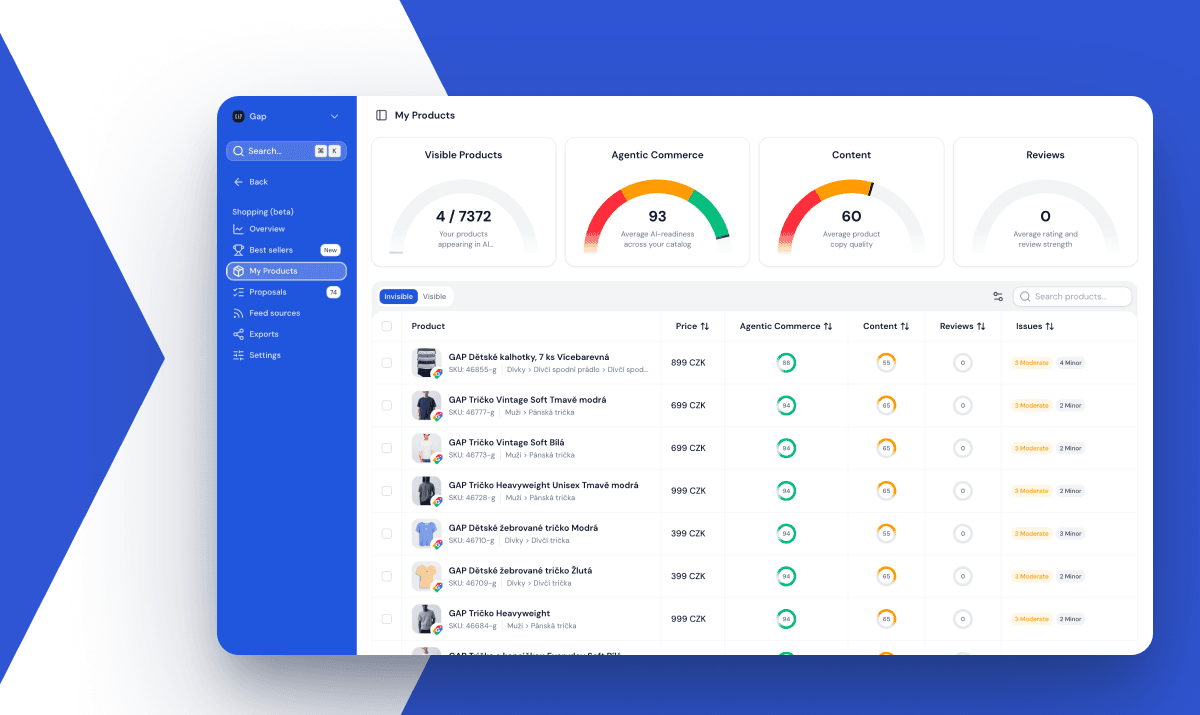
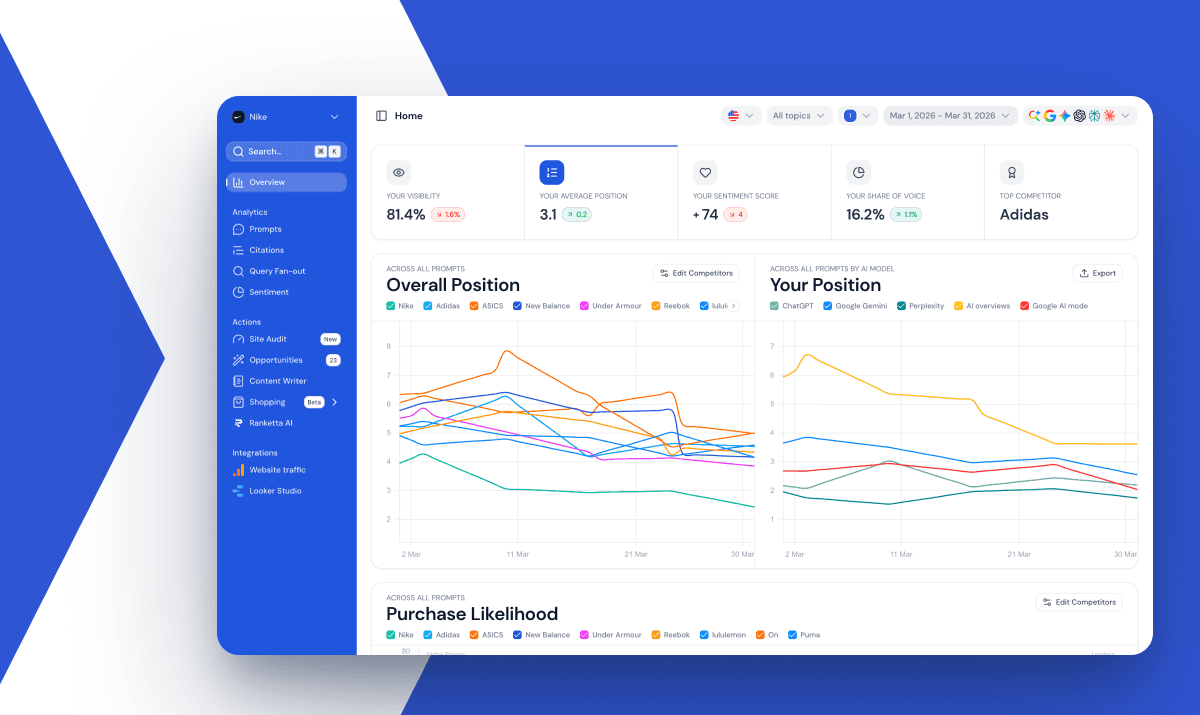
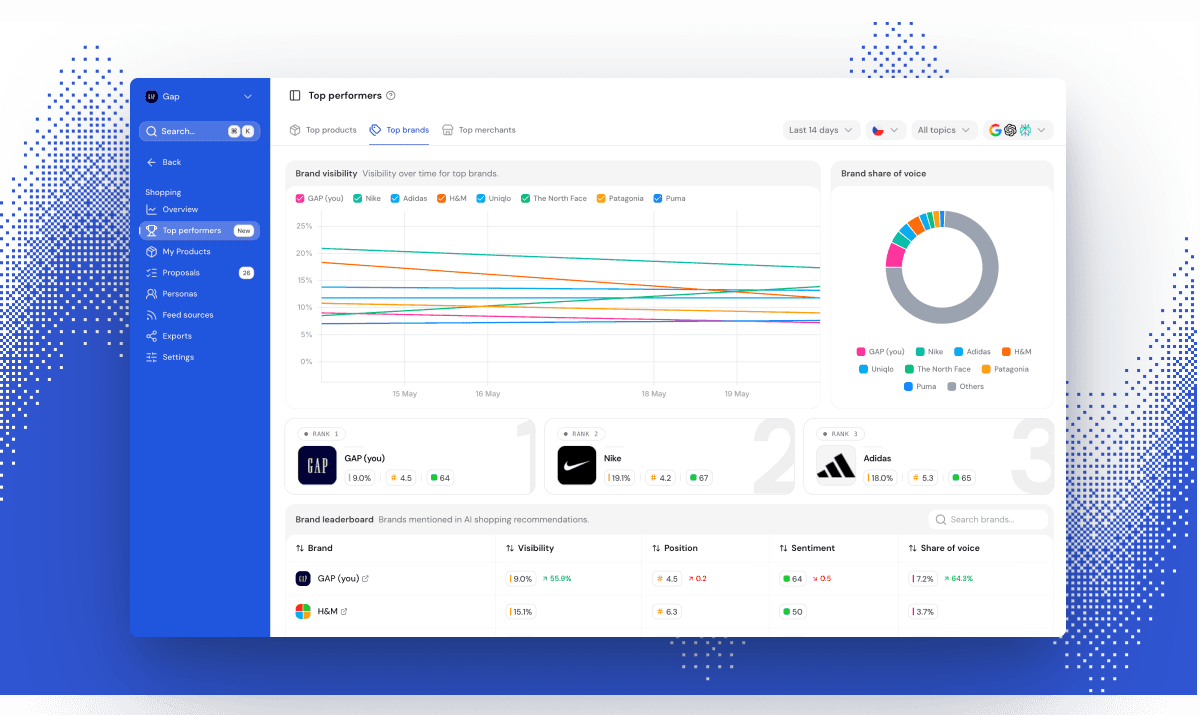
Now notice what comes out the other end. The AI doesn't recommend your brand. It recommends a specific product: "Salomon Speedcross 6 for muddy trails," not "Salomon." At Ranketta we track this visibility per SKU across ChatGPT, Perplexity, Gemini and AI Overviews. Two products from the same brand, on the same site, can land on opposite sides of the visibility line, and product data is usually a big part of why.
Which is why this is product-level work, and why the fixes below start with your individual listings rather than your brand story.
1. Get the fundamentals complete and identifiable
Before any clever optimization, the basics have to be solid.
Title, price, availability, brand, and above all a GTIN on every product that has one. The GTIN matters more than it looks. It's the universal identifier that lets an AI recognize your product as the same item that shows up on a comparison site, in a manufacturer's spec sheet, and in a pile of reviews somewhere else. Without it, the model can't connect your listing to that outside evidence, so you appear as an unknown instead of a known product with a track record.
That connection has a name: entity resolution. It's the quiet foundation under every recommendation.
Completeness is a threshold of its own, and this is where most catalogs lose. A feed that technically validates is not the same as a feed that earns AI placement. The default export from most platforms passes the basic checks and still falls short of what AI-driven discovery rewards. And the penalty isn't gradual, it's binary: in Google's system, one disapproved product can vanish from every AI shopping surface until you fix it.
The work itself is unglamorous and high-leverage:
- Audit GTIN coverage across the catalog and close the gaps.
- Check that titles, prices and availability are consistent and current.
- Get a clean, complete feed into Merchant Center if you sell through Google, and expose the same data in machine-readable form on your own pages through structured markup like schema.org.
None of this is exciting. All of it is the price of being considered at all.
2. Write descriptions around use cases, not specifications
People don't query AI in specifications. They query it in situations.
Nobody types "size 43 waterproof boot, Vibram sole." They ask for "hiking boots for long treks in wet weather." If your description is only a list of attributes, that question has nothing to grab onto.
The mechanism is semantic matching. Generative engines read the intent behind a query and match it against meaning, not exact keywords. Google has leaned into this directly: in 2026 it added conversational attributes to Merchant Center, a field built specifically for describing products the way shoppers actually talk (Google, 2026). When a platform ships a feature so you can write in plain use-case language, that tells you where the matching happens.
The fix is small. Add two or three sentences to each product covering who it's for and what it's for.
A vacuum isn't only "2000W, HEPA filter." It's "good for pet hair on carpets and stairs." A jacket isn't only "3-layer membrane." It's "for cold, rainy commutes where you're in and out of the rain all day." You keep the specs. You add a layer of meaning on top of them.
This is also where a small catalog can beat a big one. A large retailer sitting on thousands of spec-only listings is easy to leapfrog if your descriptions actually answer the question being asked.
Use-case language is the cheapest of these fixes and the one that wins the long tail.
3. Aggregate reviews and add structured FAQs
An AI trusts what other people say about your product more than what you say about it.
Reviews and customer questions read as independent signal, so they carry more weight when the model decides whether to put you forward. Your own description is a claim. An aggregated body of reviews is evidence. The gap between those two is exactly what the model is trying to close when it grounds a recommendation.
There's a second payoff hiding in this layer.
A real FAQ captures the exact phrasings people use when they're unsure, which means it answers long-tail questions your polished copy never anticipated. "Does this fit a 15-inch laptop?" "Is it machine washable?" Those are the questions that decide a purchase, and they're almost never in the marketing description.
The practical work:
- Aggregate reviews onto the product page instead of burying them.
- Build a genuine FAQ section from actual customer questions.
- Mark both up with structured data (Review and FAQPage schema) so a machine can read them cleanly.
Even a handful of honest questions and answers beats none. And since this same content lifts on-page conversion, the effort pays back twice.
Beyond your feed: off-site authority
The first three fixes live in your data. This one lives outside it, which is why it sits apart.
What third parties say about you weighs more than what you say about yourself. Models ground their answers in outside sources partly to avoid making things up, so the more consistently you're mentioned and accurately described across trusted sites, the more confidently a model treats you as a real, verifiable option. Comparison sites, review platforms, marketplaces and reference sources all feed that picture. Conflicting prices or specs across them don't just confuse shoppers, they give the model a reason to doubt you.
You can't control this layer the way you control your own feed. You can keep it clean, consistent, and present where it counts.
Why this is worth doing now
The reason to move now isn't hype. It's the quality of the traffic.
AI referrals convert better than other traffic, and not by a little. Adobe found AI referrals converting 31% more than other sources across the 2025 holiday season, with revenue per visit up 254% (Adobe, 2026). The reason is simple. A shopper arriving from an AI answer has already done their comparing. They land decided, not browsing.
The work scales with you. On ten products you do it by hand in an afternoon. On ten thousand you do it through your feed and automation. What never changes is the order: get the data clean and identifiable first, because the use-case language, the reviews, and the off-site signals all build on top of it.
Your product data isn't the paragraph under the photo. Treat it like the feed it actually is, and you give AI something it can recommend.